loading…
en/
Browse all
 by modelcontextprotocol
by modelcontextprotocol by lastmile-ai
by lastmile-ai
llm-analysis-assistant
FreeNot checkedA very streamlined mcp client that supports calling and monitoring stdio/sse/streamableHttp, and can also view request responses through the /logs page. It also

About
A very streamlined mcp client that supports calling and monitoring stdio/sse/streamableHttp, and can also view request responses through the /logs page. It also supports monitoring and simulation of ollama/openai interface.
README
1、Project Features
Through this proxy service, we can easily record the parameters and return results of the interaction with the big model, so as to conveniently analyze the logic of the client calling the big model and deeply understand the phenomenon and its essence. This project is not for optimizing the big model, but it can help you uncover the mystery of the big model, understand and achieve product market fit (PMF).
MCP is also an important part of LLM, so this project can also be used as an mcp client and supports detection of sse/mcp-streamable-http mode.
🌟 Main features
Function list:
- mcp client (already supports stdio/sse/streamableHttp calls)
- mcp initialization detection and analysis (such as Cherry Studio supports stdio/sse/streamableHttp)
- Detect ollama/openai interface and generate analysis log
- mock ollama/openai interface data
Technical features:
- uv tool use
- uvicorn framework use
- front-end async, back-end async
- log display real-time refresh, breakpoint continuation
- py socket write http client, support get/post, and their respective streaming output
- webSocket combined with asyncio use
- threading/queue use
- py program packaged into exe
- python -m llm_analysis_assistant
2. Project Background
Before the arrival of true AGI, we will have to go through a long journey, during which we will have to face constant challenges. Whether ordinary people or professionals, their lives will be changed.
However, for the use of large models, both ordinary users and developers often indirectly contact them through various clients. But the client often blocks the process of interacting with the large model, and can directly give results based on the user's simple input, giving people a feeling that the large model is mysterious, like a black box. In fact, this is not the case. When using a large model, we simply understand that we are calling an interface with input and output. It should be noted that although many inference platforms provide OpenAI format interfaces, their actual support varies. Simply put, the request parameters and return parameters of the API are not exactly the same.
For detailed parameter support, please see
Please check for other platforms
This project uses the uvicorn framework to start asgi to provide API services, with minimal dependencies, running quickly and concisely, paying tribute to the classics
3. Installation
# clone git
git clone https://github.com/xuzexin-hz/llm-analysis-assistant.git
cd llm-analysis-assistant
# Install the extension
uv sync
4. Use
Enter the root directory, then the bin directory Click run-server.cmd to start the service Click run-build.cmd to package the service into an executable file (in the dist directory) Or run the following command directly in the root directory:
#Default port 8000
python server.py
#You can also specify the port
python server.py --port=8001
#You can also specify the openai address, the default is the ollama address: http://127.0.0.1:11434/v1/
python server.py --base_url=https://api.openai.com
#If you configure other api addresses, remember to fill in the correct api_key, ollama does not need api_key by default
#--is_mock=true Turn on mock and return mock data
python server.py --is_mock=true
#--mock_string, you can customize the returned mock data, if you do not set this item, the default mock data will be returned. This parameter also applies to non-streaming output
python server.py --is_mock=true --mock_string=Hello
#--mock_count, the number of times the mock returns data when streaming output, the default is 3 times
python server.py --is_mock=true --mock_string=Hello --mock_count=10
#--single_word, mock streaming output return effect, the default is to divide a sentence into 3 parts according to [2:5:3] and return them in sequence, after setting the second parameter, it will be a word-by-word streaming output effect
python server.py --is_mock=true --mock_string=你好啊 --single_word=true
#--looptime, mock streaming output return data interval, the default is 0.35 seconds, set looptime=1 when streaming output display data speed will be slow
python server.py --is_mock=true --mock_string=你好啊 --looptime=1
Using uv (recommended)
When using uv no specific installation is needed. We will use uvx to directly run llm-analysis-assistant.
uvx llm_analysis_assistant
Using PIP(🌟)
Alternatively you can install llm-analysis-assistant via pip:
pip install llm-analysis-assistant
After installation, you can run it as a script using:
python -m llm_analysis_assistant
http://127.0.0.1:8000/logs View logs in real time
Detection, analysis and call mcp (currently supports stdio/sse/streamableHttp)
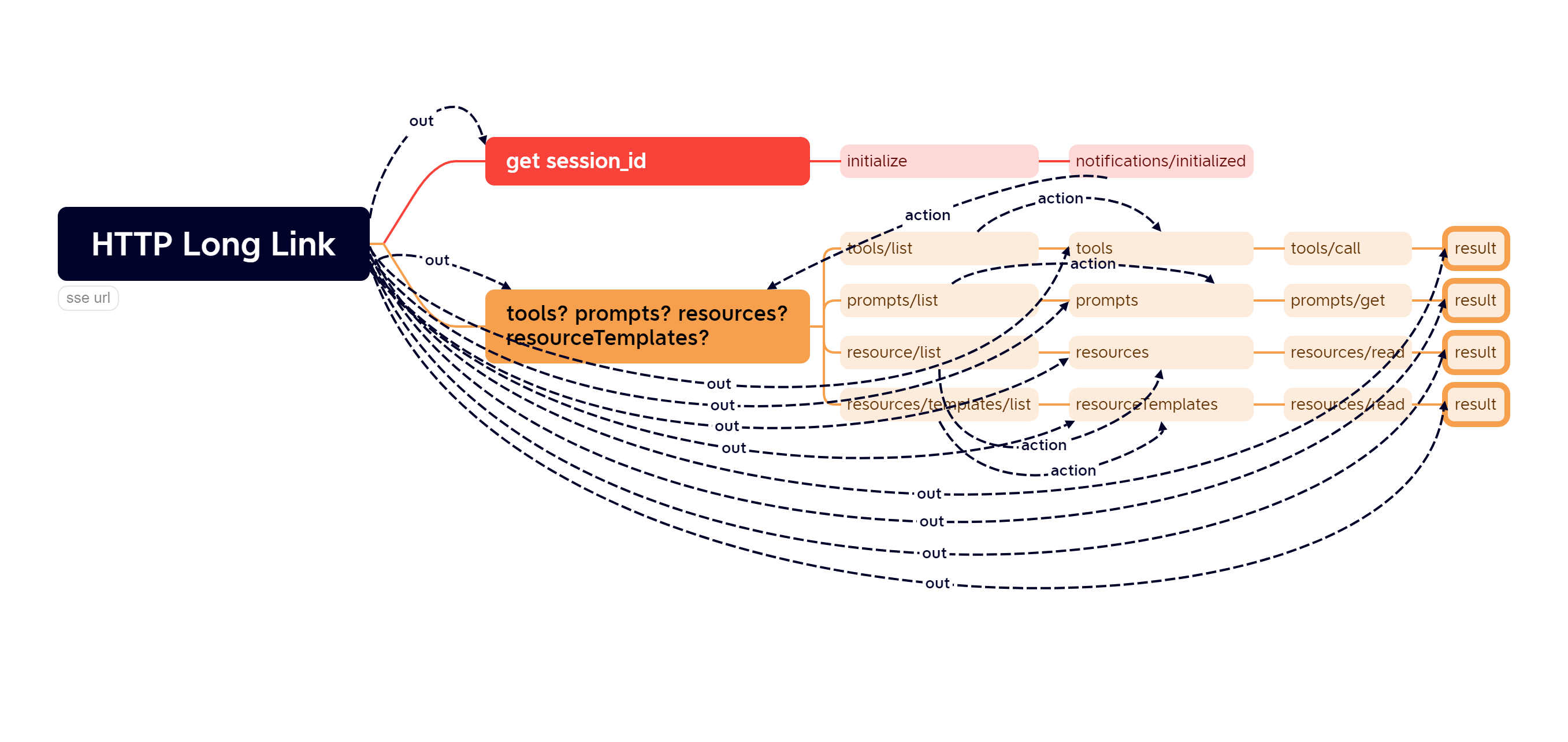
The implementation logic of mcp client technology is as follows. The interface log seems to be a sequential request, but it is not actually a simple request-response mode. This is easier for users to understand
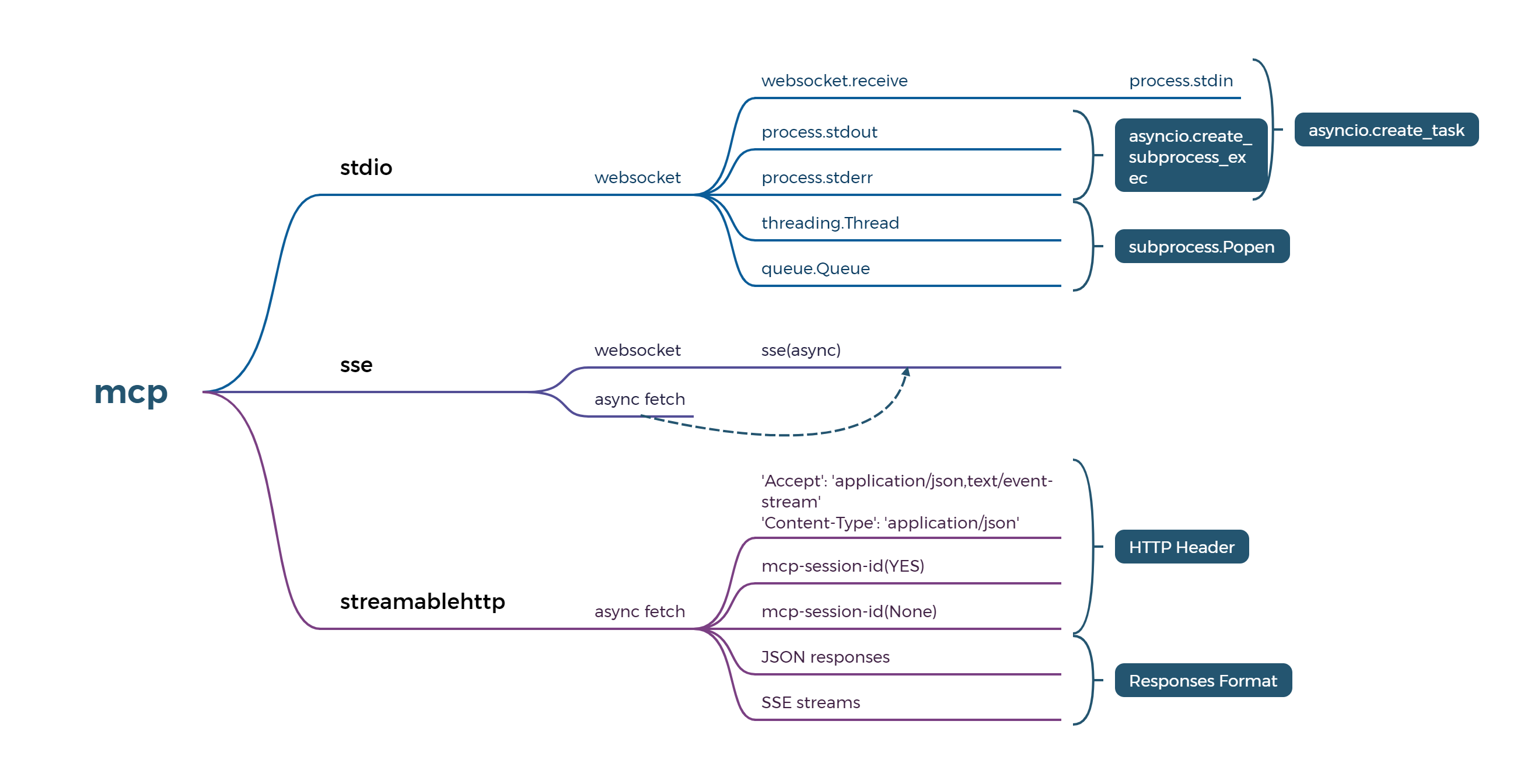
mcp-sse logic details (for similarities and differences with stdio/streamableHttp, please refer to other materials)
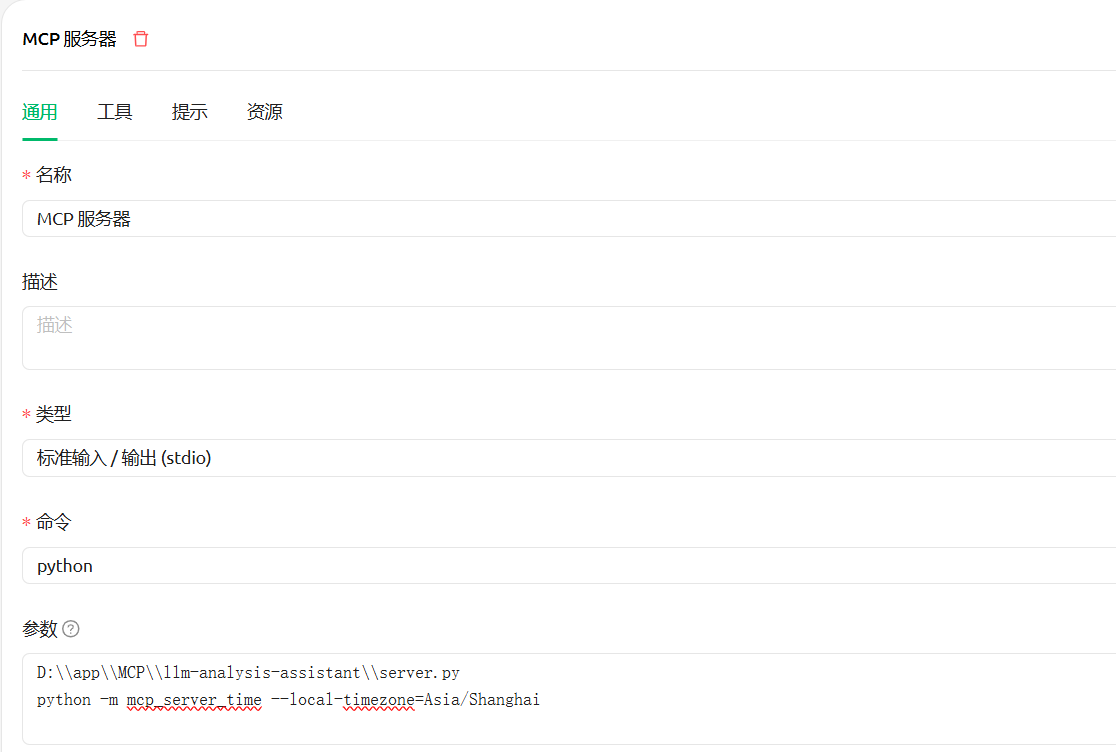
Detection and analysis of mcp-stdio
Open the following address in the browser. In the command line, ++user=xxx means that the system variable is user and the value is xxx
http://127.0.0.1:8000/mcp?url=stdio
Or use Cherry Studio to add the stdio service
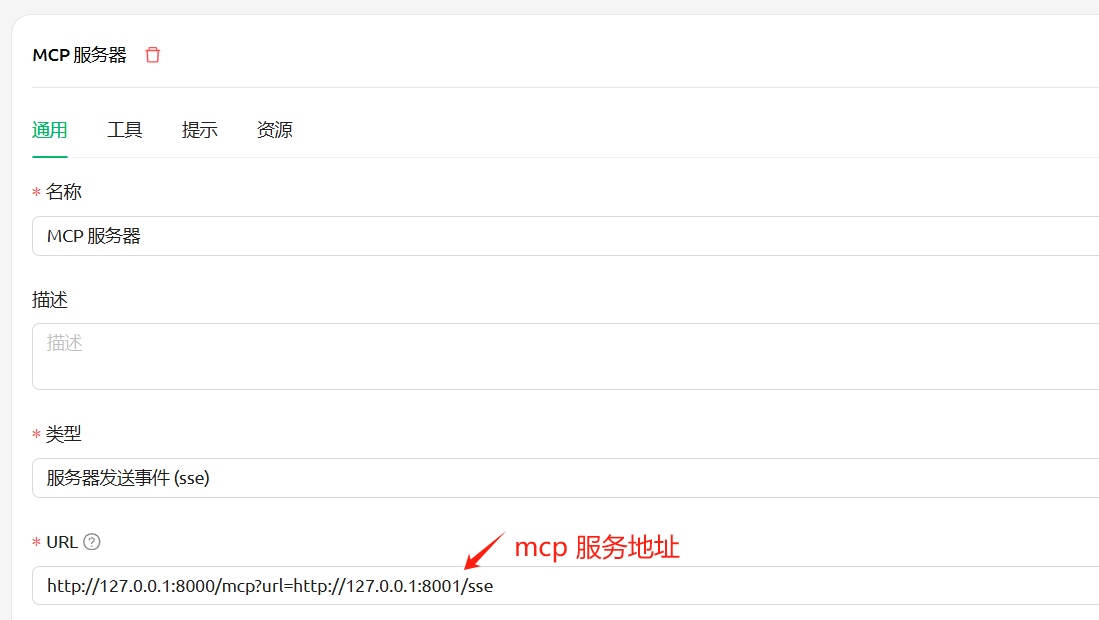
Detection and analysis of mcp-sse
Open the following address in the browser, the url is the sse service address
http://127.0.0.1:8000/mcp?url=http://127.0.0.1:8001/sse
http://127.0.0.1:8000/mcp?url=http://127.0.0.1:8002/sse?++user=xxx # ++user=xxx in the url means the HTTP request header user value is xxx
Or use Cherry Studio to add the mcp service
Detection and analysis of mcp-streamable-http
Open the following address in the browser, the url is the streamableHttp service address
http://127.0.0.1:8000/mcp?url=http://127.0.0.1:8001/mcp
http://127.0.0.1:8000/mcp?url=http://127.0.0.1:8001/mcp?++user=xxx # ++user=xxx in the url means the HTTP request header user value is xxx
Or use Cherry Studio to add the mcp service

When using Cherry Studio, you can http://127.0.0.1:8000/logs View the logs in real time to analyze the calling logic of sse/mcp-streamable-http
5. Example collection
Change the base_url of openai to the address of the service: http://127.0.0.1:8000
⑴. Analyze langchain
Install langchain first:
pip install langchain langchain-openai
from langchain.chat_models import init_chat_model
model = init_chat_model("qwen2.5-coder:1.5b", model_provider="openai",base_url='http://127.0.0.1:8000',api_key='ollama')
model.invoke("Hello, world!")
After running the above code, if you want to view the log file, you can enter the corresponding day folder in the logs directory to view it. There is a log file for each request
Open http://127.0.0.1:8000/logs to view the logs in real time
⑵Analysis tool set
1. Tool Open WebUI
2. Tool Cherry Studio
3. Tool continue
4. Tool Navicat
⑶、Analysis agent
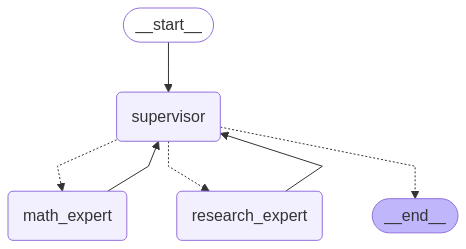
1. Agent Multi-Agent Supervisor
####### Agent is a node, agent is a tool, leader mode
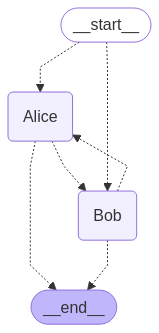
2. Intelligent agent Multi-Agent Swarm
Professional matters are reliable when handed over to professionals, teamwork mode
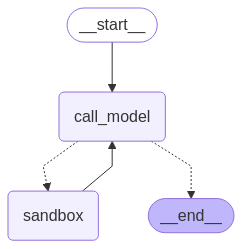
3. Intelligent agent codeact
####### Every inch has its own strengths and weaknesses (it is said that CodeAct will greatly improve accuracy and efficiency in some scenarios)
License
Install llm-analysis-assistant in Claude Desktop, Claude Code & Cursor
Run in your terminal:
claude mcp add llm-analysis-assistant -- npx FAQ
Is llm-analysis-assistant MCP free?
Yes, llm-analysis-assistant MCP is free — one-click install via Unyly at no cost.
Does llm-analysis-assistant need an API key?
No, llm-analysis-assistant runs without API keys or environment variables.
Is llm-analysis-assistant hosted or self-hosted?
Self-hosted: the server runs locally on your machine via the install command above.
How do I install llm-analysis-assistant in Claude Desktop, Claude Code or Cursor?
Open llm-analysis-assistant on unyly.org, pick your client tab (Claude Desktop, Claude Code, Cursor) and press Install — the config is generated automatically, no JSON editing.
Related MCPs
Fetch
Web content fetching and conversion for efficient LLM usage.
by Community
AWS KB Retrieval
Retrieval from AWS Knowledge Base using Bedrock Agent Runtime.
by modelcontextprotocolSpring AI MCP Server
Provides auto-configuration for setting up an MCP server in Spring Boot applications.
by Community
MCP-Agent
A simple, composable framework to build agents using Model Context Protocol by [LastMile AI](https://www.lastmileai.dev)
by lastmile-aiCompare llm-analysis-assistant with
Not sure what to pick?
Find your stack in 60 seconds
Author?
Embed badge for your README
Browse similar
All ai MCPs